借着这次的CVE-2025-1097、CVE-2025-1098、CVE-2025-24514、CVE-2025-1974填一下19年留下的陈年云相关的老坑,docker部分也同样会找机会补全 (K8s的部分因为没丢到当时的博客导致和早年的固件笔记一起丢了) ,从kubernetes相对基础的部分入手,讲一下常见的核心功能,最后以CVE-2025-1974几个漏洞产生的原理和过程为终点,目的是借着机会复习下k8s的一些组件,因为是摸鱼时候才会写写所以会断断续续的更新这个笔记。(全记到blog这样笔记就不会再丢了) 。
正文
CVE参考wiz文章内容https://www.wiz.io/blog/ingress-nginx-kubernetes-vulnerabilities
这里着重探讨危害相对较高的CVE-2025-1974XD
首先,需要理解的是CVE-2025-24514,因为CVE-2025-1974..等几个漏洞的利用基本都建立在CVE-2025-24514(Ingress NGINX Admission 处理AdmissionReview请求时字段未过滤,导致可通过注释注入 ) 或类似的思路之上。
而在CVE-2025-24514之前,要先了解Ingress NGINX
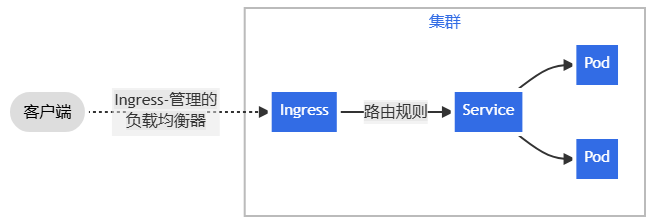
站在对外暴露服务的映射角度来看,Ingress 和service 分别对应了常规7层模型里的七层和四层,但其二者在kubernetes中实际架构中是上下层关系,后面也会讲到这部分。
(图片偷自 https://kubernetes.io/zh-cn/docs/concepts/services-networking/ingress/ )
总之,我会从service开始,因为其相对基础;再经过Ingress NGINX,admission controller
tips 文章中的实验我都会用minikube来做,会方便很多,用法参考下文
https://minikube.sigs.k8s.io/docs/start/?arch=%2Flinux%2Fx86-64%2Fstable%2Fbinary+download#take-the-next-step
其实用docker来拉minikube的话不需要安装这么多依赖,不过还是列出来方便其他部署方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sudo yum install docker-ce docker-ce-cli containerd.io sudo systemctl start docker sudo yum install -y conntrack wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.32.0/crictl-v1.32.0-linux-amd64.tar.gz sudo tar zxvf crictl-v1.32.0-linux-amd64.tar.gz -C /usr/sbin wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.16/cri-dockerd-0.3.16.amd64.tgz tar -zxvf cri-dockerd-0.3.16.amd64.tgz sudo cp cri-dockerd /usr/local/bin/cri-dockerd wget https://raw.githubusercontent.com/Mirantis/cri-dockerd/refs/heads/master/packaging/systemd/cri-docker.service wget https://raw.githubusercontent.com/Mirantis/cri-dockerd/refs/heads/master/packaging/systemd/cri-docker.service sudo install ./* /etc/systemd/system sudo sed -i -e 's,/usr/bin/cri-dockerd,/usr/local/bin/cri-dockerd,' /etc/systemd/system/cri-docker.service sudo systemctl daemon-reload sudo systemctl restart cri-docker sudo yum install containernetworking-plugins wget https://github.com/containernetworking/plugins/releases/download/v1.6.2/cni-plugins-linux-amd64-v1.6.2.tgz CNI_PLUGIN_INSTALL_DIR="/opt/cni/bin" sudo mkdir -p "$CNI_PLUGIN_INSTALL_DIR " sudo tar -xf cni-plugins-linux-amd64-v1.6.2.tgz -C "$CNI_PLUGIN_INSTALL_DIR "
这里为了方便我选择docker拉服务,测试环境是ubuntu24.10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 curl -LO https://github.com/kubernetes/minikube/releases/latest/download/minikube-linux-amd64 sudo install minikube-linux-amd64 /usr/local/bin/minikube && rm minikube-linux-amd64 sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \ $(. /etc/os-release && echo "$VERSION_CODENAME " ) stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo sed -i 's/debian/ubuntu/g' /etc/apt/sources.list.d/docker.list sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io minikube start --driver=docker --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers minikube start --driver=docker --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers --bas e-image="registry.cn-hangzhou.aliyuncs.com/google_containers/kicbase:v0.0.46" --memory=2066mb minikube kubectl -- get pods -A
装完确定pod都活着就ok了
1 2 3 4 5 6 7 8 9 10 test @test :~$ minikube kubectl -- get pods -ANAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-668d6bf9bc-82gm2 1/1 Running 0 10m kube-system coredns-668d6bf9bc-sxmjq 1/1 Running 0 10m kube-system etcd-minikube 1/1 Running 0 10m kube-system kube-apiserver-minikube 1/1 Running 0 10m kube-system kube-controller-manager-minikube 1/1 Running 0 10m kube-system kube-proxy-n4r7d 1/1 Running 0 10m kube-system kube-scheduler-minikube 1/1 Running 0 10m kube-system storage-provisioner 1/1 Running 1 (10m ago) 10m
service 还是以官方文档对service 的介绍为主,
官方对其的定义是
将在集群中运行的应用通过同一个面向外界的端点公开出去,即使工作负载分散于多个后端也完全可行
这里的场景通常是指的一个或一组pod,service可以将这样的一个pod集合公开出去(Cluster IP)用于其他pod交互等,同时,service也定义着外部访问到这些pod集合的策略,*官方文档中将每个定义的service视为一个端点(通常是指pod)的逻辑集合*。
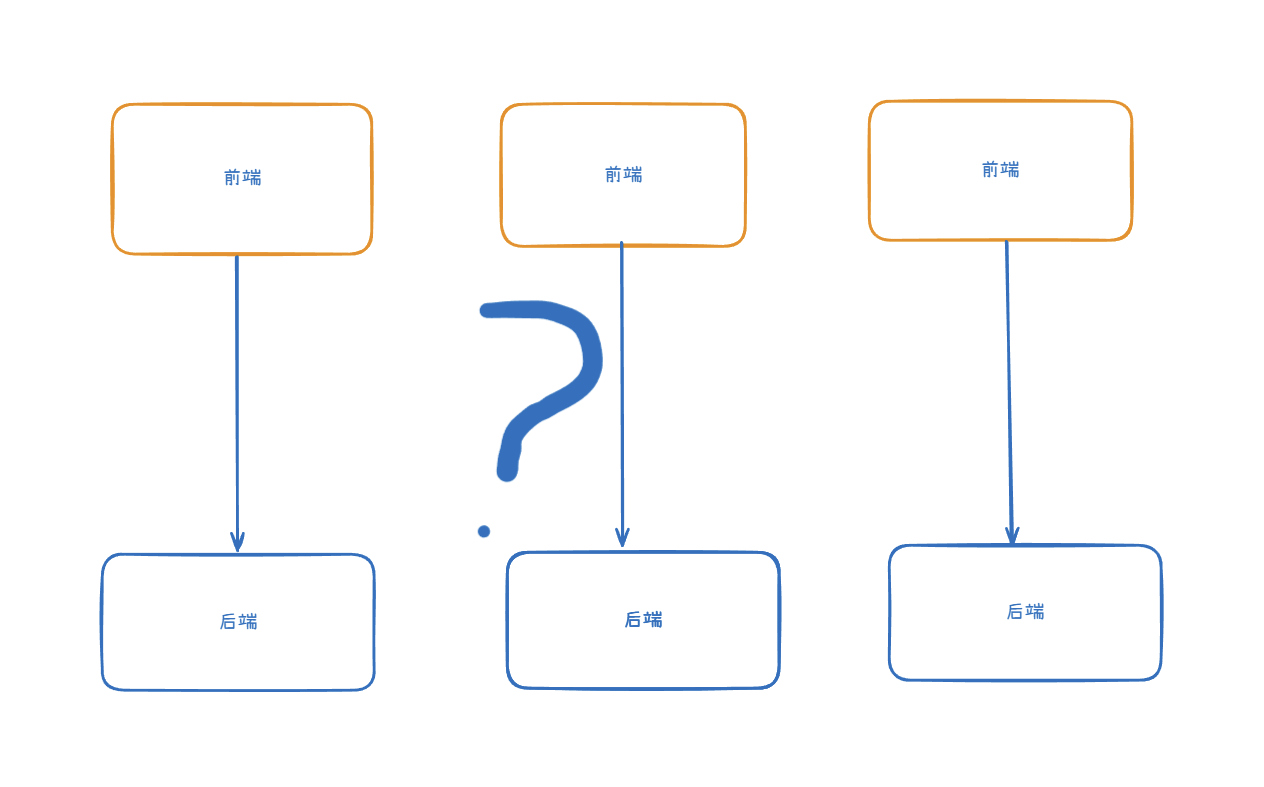
官网文档中举了一个比较实际的例子:前端pod与后端pod之间交互 。
思考一下,在每个后端pod的ip都不相同的情况下,如果没有service将后端pod集合为一个ip点位,前端pod如何和后端pod进行连接交互。
总不能像图上这样每个前端都绑定一个后端点位的ip。能不能通信先不说,如果对应的后端点位挂了那前端对应的个pod也就没法用了,有些荒谬的同时这也违背了pod高可用属性的设计初衷。
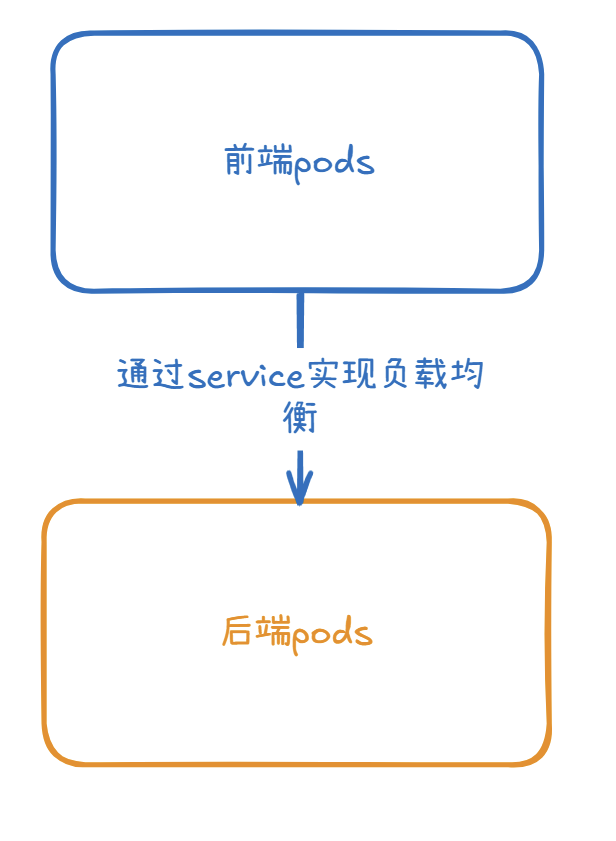
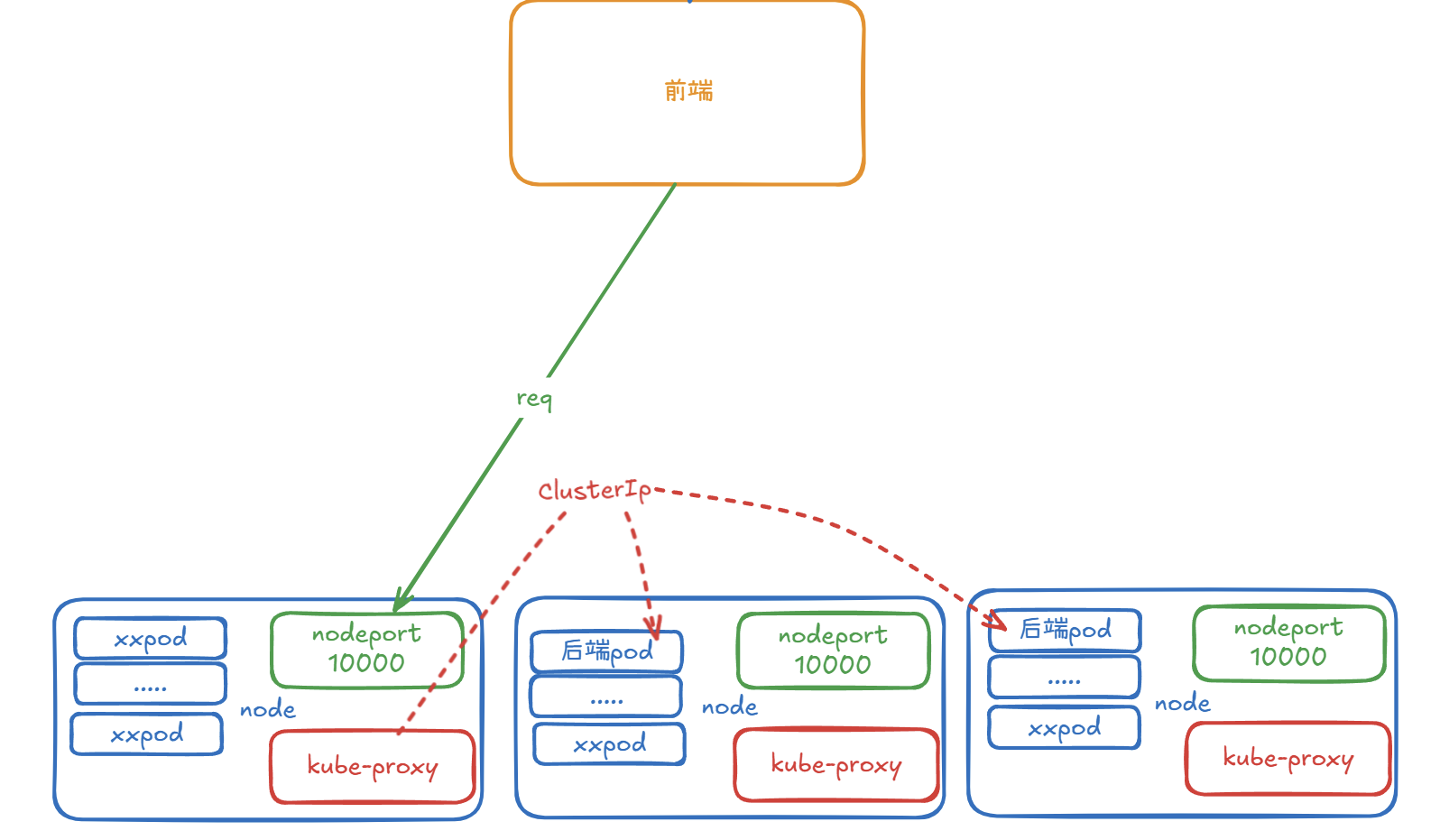
那service的出现就解决了这种问题,通过service我们可以将一组同类型的pod作为集合,映射为一个ip,前端pod与后端pod交互时,并不需要在意自己交互的是哪一个后端pod,因为后端pod随时可能发生变更所以也没必要在意,service会将流量负载均衡到后端pod组 或 请求发送到某个node节点上的nodeport端口走到kube-proxy再转发到集群中service给其对应的cluster IP而后kubeproxy再根据其负载均衡走到某个node的一个后端服务pod中(nodeport类型).
(nodeport形式)
需要注意Cluster ip和kube-proxy都是通过api server获取更新的,这里图我是用nodeport模式画的,每个node都会给这个pod集合对应的service开个端口监听,然后收到的请求从nodeport进来会经过kube-proxy转到这个service对应的clusterIP然后再通过其在Endpoints表和具体的负载算法,通过cni(Calico、Flannel)直接走到指定node中的pod
kube-proxy更新频率受到pod迭代影响,其而且其也会通过kubelet监控Endpoints动态更新自己的规则表,通常clusterIP在创建后除非对应serivce删了,不然一般不会变动
service支持多种公开方式或者说服务类型,如下
1 2 3 4 5 6 7 8 9 10 11 ClusterIP 通过集群的内部 IP 公开 Service,选择该值时 Service 只能够在集群内部访问。 这也是你没有为 Service 显式指定 type 时使用的默认值。 你可以使用 Ingress 或者 Gateway API 向公共互联网公开服务。 NodePort 通过每个节点上的 IP 和静态端口(NodePort)公开 Service。 为了让 Service 可通过节点端口访问,Kubernetes 会为 Service 配置集群 IP 地址, 相当于你请求了 type: ClusterIP 的 Service。 LoadBalancer 使用云平台的负载均衡器向外部公开 Service。Kubernetes 不直接提供负载均衡组件; 你必须提供一个,或者将你的 Kubernetes 集群与某个云平台集成。 ExternalName 将服务映射到 externalName 字段的内容(例如,映射到主机名 api.foo.bar.example)。 该映射将集群的 DNS 服务器配置为返回具有该外部主机名值的 CNAME 记录。 集群不会为之创建任何类型代理。
ClusterIP 首先是默认的ClusterIp,这个是service默认的配置类型,也是其他几个类型的实现基础。
虽然是基础,但他也会更方便理解service的特性,或者说是理解pod与service的关系
这里yaml我的创建两个ng的pod,然后起了个service指关联到这组pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 test@test:~/k8s_yaml$ cat Deployment-nginx-ClusterIP.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: registry.cn-hangzhou.aliyuncs.com/acs-sample/nginx:latest ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-service labels: app: nginx spec: selector: app: nginx ports: - protocol: TCP port: 80 targetPort: 80 type: ClusterIP
然后拉起来
1 2 3 test @test :~/k8s_yaml$ kubectl apply -f Deployment-nginx-ClusterIP.yaml deployment.apps/nginx-deployment created service/nginx-service created
查看当前pod状态,只创建了俩,能看到都正常跑起来了
1 2 3 4 test @test :~/k8s_yaml$ kubectl get pods NAME READY STATUS RESTARTS AGE nginx-deployment-6c7848d5b5-fxp6d 1/1 Running 0 9s nginx-deployment-6c7848d5b5-kdw46 1/1 Running 0 9s
然后是service状态,能看到已经定义的nginx-service已经跑起来了,这里ClusterIP的用处一会讲到
1 2 3 4 test @test :~/k8s_yaml$ kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d21h nginx-service ClusterIP 10.107.205.193 <none> 80/TCP 1m
然后就是一个问题,我们要访问到服务的话该如何访问?
这里可以用port-forward来将服务端口映射出来
但有两种转发方式,分别是
一、转发pod端口 这里转发pod端口指的是:转发指定一个pod的某个端口至某个地址某个端口
比如这里我们的两个ng的pod
1 2 3 4 test @test :~/k8s_yaml$ kubectl get podsNAME READY STATUS RESTARTS AGE nginx-deployment-6c7848d5b5-fxp6d 1/1 Running 0 144m nginx-deployment-6c7848d5b5-kdw46 1/1 Running 0 144m
我们用转发pod的方式先看下
这里选定一个pod将其80端口转发出来,至当前的8888口
1 2 3 test @test :~/k8s_yaml$ kubectl port-forward pod/nginx-deployment-6c7848d5b5-fxp6d --address 0.0.0.0 8888:80 Forwarding from 0.0.0.0:8888 -> 80 Handling connection for 8888
这时可以访问本地8888端口来访问到pod内80口的应用
1 2 3 4 5 6 7 8 9 10 11 curl 192.168.221.130:8888 -is HTTP/1.1 200 OK Server: nginx/1.13.3 Date: Tue, 01 Apr 2025 09:16:37 GMT Content-Type: text/html Content-Length: 612 Last-Modified: Tue, 11 Jul 2017 13:06:07 GMT Connection: keep-alive ETag: "5964cd3f-264" Accept-Ranges: bytes
或许也会注意到,采用这种方式,这样仅是用了一个pod,但我们有两个pod,用这种方式是没法做到高可用的。
那service基础的ClusterIP模式,就是为了解决这一问题而出现的.
二、ClusterIP 1 2 3 4 test @test :~/k8s_yaml$ kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d21h nginx-service ClusterIP 10.107.205.193 <none> 80/TCP 1m
可以看下,这里刚创建的name为nginx-service的service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 test @test :~/k8s_yaml$ kubectl describe svc nginx-serviceName: nginx-service Namespace: default Labels: app=nginx Annotations: <none> Selector: app=nginx Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.107.205.193 IPs: 10.107.205.193 Port: <unset > 80/TCP TargetPort: 80/TCP Endpoints: 10.244.0.12:80,10.244.0.13:80 Session Affinity: None Internal Traffic Policy: Cluster Events: <none>
因为我们在创建这个service时将选择器(Selector)连接指向到了标签为app=nginx的pod
通过这个标签再查询相关的pod,这也正是我们刚创建时候打了app=nginx的这俩pod
1 2 3 4 test @test :~/k8s_yaml$ kubectl get pods --selector='app=nginx' NAME READY STATUS RESTARTS AGE nginx-deployment-6c7848d5b5-fxp6d 1/1 Running 0 4h58m nginx-deployment-6c7848d5b5-kdw46 1/1 Running 0 4h58m
或者这样看也行
1 2 3 test @test :~$ kubectl get endpoints nginx-serviceNAME ENDPOINTS AGE nginx-service 10.244.0.12:80,10.244.0.13:80 5h36m
这里如果通过port-forward直接转发service/nginx-service的端口是不行的,会发现只有一个pod的ng能够收到请求,这是因为端口转发时,kubectl会先查询服务对应的所有 pod,然后随机(或按照一定规则)选择其中一个 pod。
所有经由该port-forward的请求都会被固定地转发到这个选中的pod上,后续请求不会在多个 pod 之间做负载均衡。
基础的ClusterIP类型仅是从集群内部访问时才是轮询负载的,如果要实现外部访问也是负载均衡,则需要选择用建立在其之上的Nodeport类型或LoadBalancer,亦或者是使用与这个漏洞相关联的ingress,之后都会讲到。
为了方便理解这里就不用kubectl proxy走apiserver访问了,这里我选择临时拉个busybox从集群内访问会更直观一下
1 2 3 test @test :~/k8s_yaml$ kubectl run busybox-pod-1 --rm -it --image=docker.m.daocloud.io/library/busybox:latest -- /bin/shIf you don't see a command prompt, try pressing enter. / #
确定一下svc的ip 10.105.131.184
1 nginx-service ClusterIP 10.105.131.184 <none> 80/TCP 56m
然后从busyboxpod对nginx-service的ClusterIP发起访问
1 / # for i in `seq 0 60`;do wget 10.105.131.184:80 1>&2 2>/dev/null ;done
查看两个pod日志,会发现请求的流量是基本均匀分布开的。
ClusterIP服务本身没有负载均衡功能,这部分通过是kube-proxy来负载到后面pod的,kube-proxy会捕获到至ClusterIP的流量,依照当前ipvs或者iptables的网络规则匹配目的地址和端口,并依据负载规则决定将请求重定向至哪个目的pod。
参考官方文档对于这部分的阐述
https://kubernetes.io/docs/reference/networking/virtual-ips/
这里kube-proxy如果用的iptables是仅支持轮询的负责方式,而ipvs则玩的会比较花,相对的service越多的话iptables的性能会更显著一些。
这里我因为是docker拉的 k8s 所以需要看下kube-proxy-pod的信息才能确认用的是ipvs还是iptables.
1 2 3 4 5 test @test :~/k8s_yaml$ kubectl describe pods kube-proxy-n4r7d -n kube-system|grep -i command -A10 Command: /usr/local/bin/kube-proxy --config=/var/lib/kube-proxy/config.conf --hostname-override=$(NODE_NAME)
这里并没有直接通过--proxy-mode指定模式,所以还要进一步看config.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 test @test :~/k8s_yaml$ kubectl exec -n kube-system kube-proxy-n4r7d -- cat /var/lib/kube-proxy/config.confapiVersion: kubeproxy.config.k8s.io/v1alpha1 bindAddress: 0.0.0.0 bindAddressHardFail: false clientConnection: acceptContentTypes: "" burst: 0 contentType: "" kubeconfig: /var/lib/kube-proxy/kubeconfig.conf qps: 0 clusterCIDR: 10.244.0.0/16 configSyncPeriod: 0s conntrack: maxPerCore: 0 min: null tcpBeLiberal: false tcpCloseWaitTimeout: 0s tcpEstablishedTimeout: 0s udpStreamTimeout: 0s udpTimeout: 0s detectLocal: bridgeInterface: "" interfaceNamePrefix: "" detectLocalMode: "" enableProfiling: false healthzBindAddress: "" hostnameOverride: "" iptables: localhostNodePorts: null masqueradeAll: false masqueradeBit: null minSyncPeriod: 0s syncPeriod: 0s ipvs: excludeCIDRs: null minSyncPeriod: 0s scheduler: "" strictARP: false syncPeriod: 0s tcpFinTimeout: 0s tcpTimeout: 0s udpTimeout: 0s kind: KubeProxyConfiguration logging: flushFrequency: 0 options: json: infoBufferSize: "0" text: infoBufferSize: "0" verbosity: 0 metricsBindAddress: 0.0.0.0:10249 mode: "" nftables: masqueradeAll: false masqueradeBit: null minSyncPeriod: 0s syncPeriod: 0s nodePortAddresses: null oomScoreAdj: null portRange: "" showHiddenMetricsForVersion: "" winkernel: enableDSR: false forwardHealthCheckVip: false networkName: "" rootHnsEndpointName: ""
能看到mode:并没有给值,所以是默认的iptables,这里iptabes只支持基础的负载
1 在此模式下,kube-proxy 使用内核 netfilter 子系统的 iptables API 配置数据包转发规则。对于每个端点,它会安装 iptables 规则,默认情况下会随机选择一个后端 Pod
iptables也只能在conf改动一部分规则同步优化的内容,这里面用的相对多的是minSyncPeriod、masqueradeAll、syncPeriod其他的其实用的比较少,但可见并没有负载相关的配置供修改
这部分可以参考下文
https://kubernetes.io/docs/reference/config-api/kube-proxy-config.v1alpha1/#kubeproxy-config-k8s-io-v1alpha1-KubeProxyIPTablesConfiguration
南无三、此间事于《库伯-普肉瑟斯/挨批忒宝斯》源码中——壹仟陆佰叁拾行间亦有记载
https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/iptables/proxier.go#L1630
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 numEndpoints := len (endpoints) for i, ep := range endpoints { epInfo, ok := ep.(*endpointInfo) if !ok { continue } comment := fmt.Sprintf(`"%s -> %s"` , svcPortNameString, epInfo.String()) args = append (args[:0 ], "-A" , string (svcChain)) args = proxier.appendServiceCommentLocked(args, comment) if i < (numEndpoints - 1 ) { args = append (args, "-m" , "statistic" , "--mode" , "random" , "--probability" , proxier.probability(numEndpoints-i)) } natRules.Write(args, "-j" , string (epInfo.ChainName)) } }
那有没有在这部分能弥补处理负载策略的模式呢
有的,兄弟有的
与iptables相对的ipvs则可以按照我们的自定义做出符合场景的负载模式处理。
2025年4月7日留: service部分没写完,下一次摸鱼时候会更新